The theme of the Large Language Models (LLMs) reading group’s fifth presentation is about human alignment. Hongliang, the presenter for this session, covered instruction generation methods, popular alignment approaches, and discussed the limitations of current human alignment.
When using LLMs and their related applications, we are concerned about the extent to which the model’s behaviour and outputs align with human values, intentions, and expectations. The process of addressing and removing these undesired behaviours is referred to as alignment.
In her presentation, instruction generation approaches such as Self-Alignment will automatically produce high-quality instructions by incorporating manual principles. Language models will adhere to these principles and develop internal thoughts to achieve Principle-Driven Self-Alignment, thus generating direct and detailed instructions.
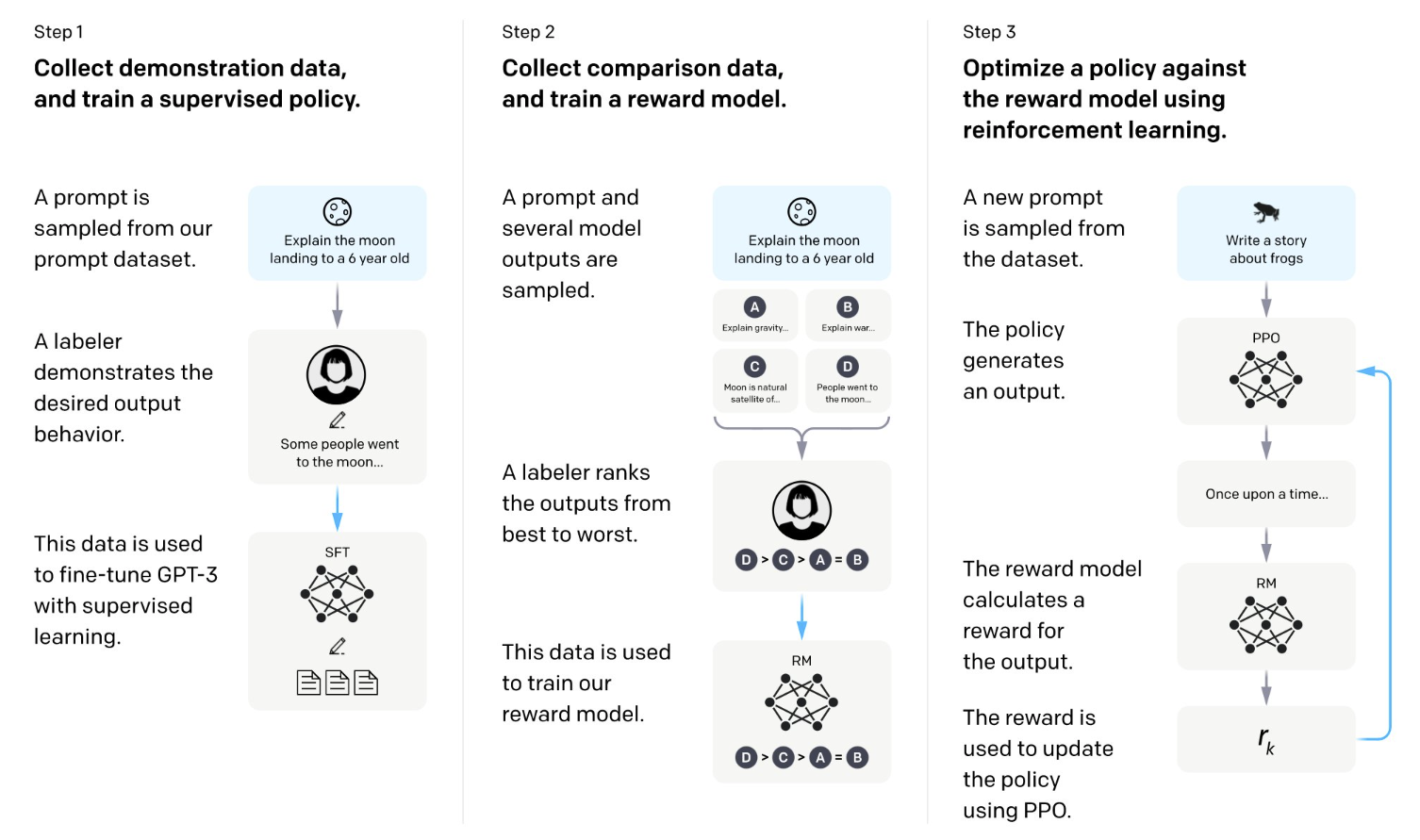
Furthermore, Hongliang also covered the some popular fine-tuning method for LLMs, such as Reinforcement Learning from Human Feedback (RLHF). RLHF helps the language model’s parameters integrate with human-preference training objectives by introducing human intelligence. The core of RLHF involves incorporating comparative rankings provided by humans into the pre-training process. Despite the widespread adoption of this method, Hongliang also points out that RLHF lacks suboptimal information, which fails to reflect values held by different demographic groups.
Towards the end of the presentation, the limitations of alignment in LLMs were discussed. On one hand, the distinction has increased due to the application of fine-tuning methods like RLHF, which enhances the effectiveness of LLMs and brings them closer to users’ intentions. On the other hand, this heightened distinguishability makes it easier for undesired behaviours from LLMs to be triggered through adversarial prompts. These challenges underscore the significance of addressing human alignment.
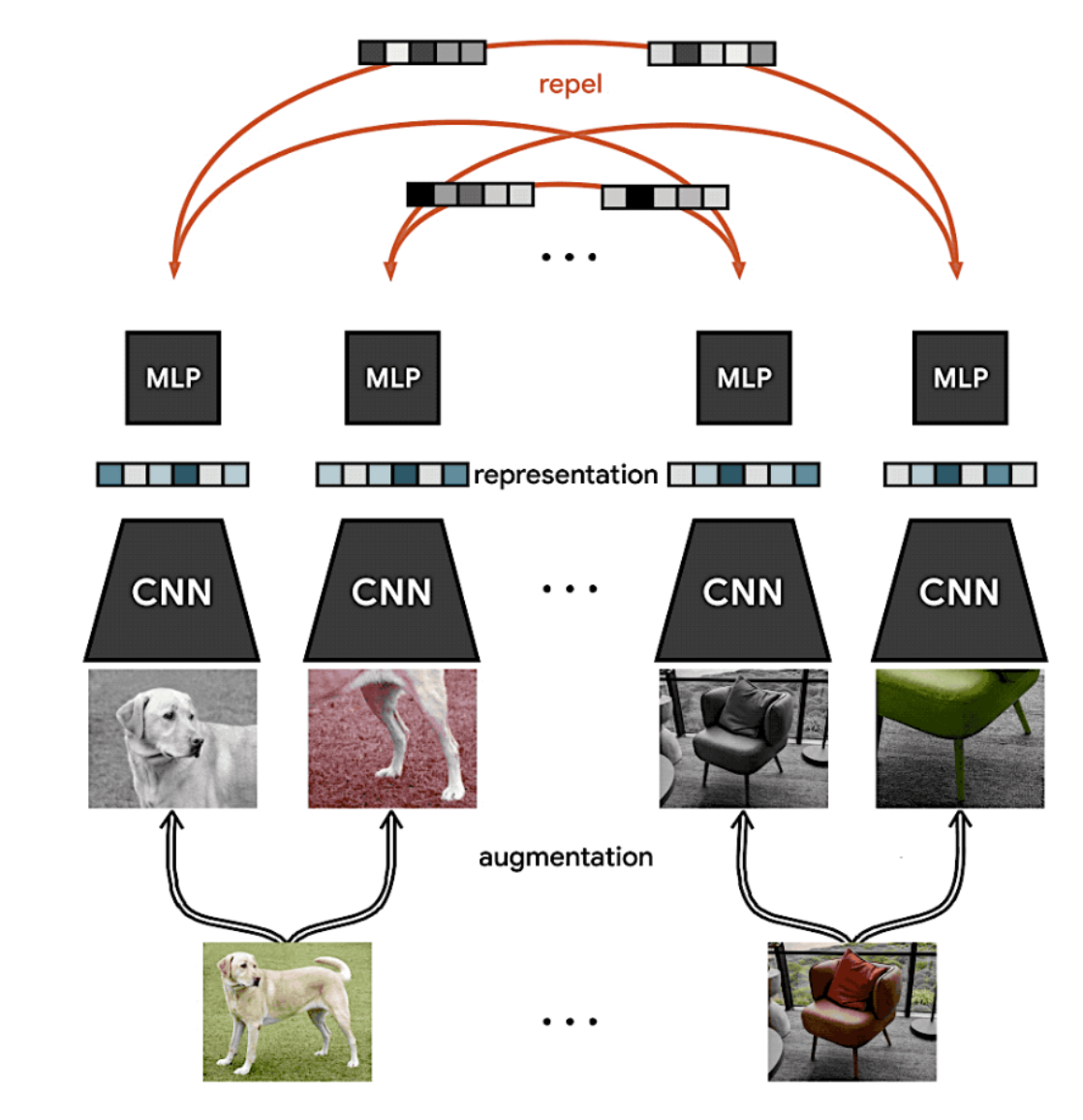 ML Reading Group Series: Self-Supervised Contrastive Learning in Computer Vision
ML Reading Group Series: Self-Supervised Contrastive Learning in Computer Vision