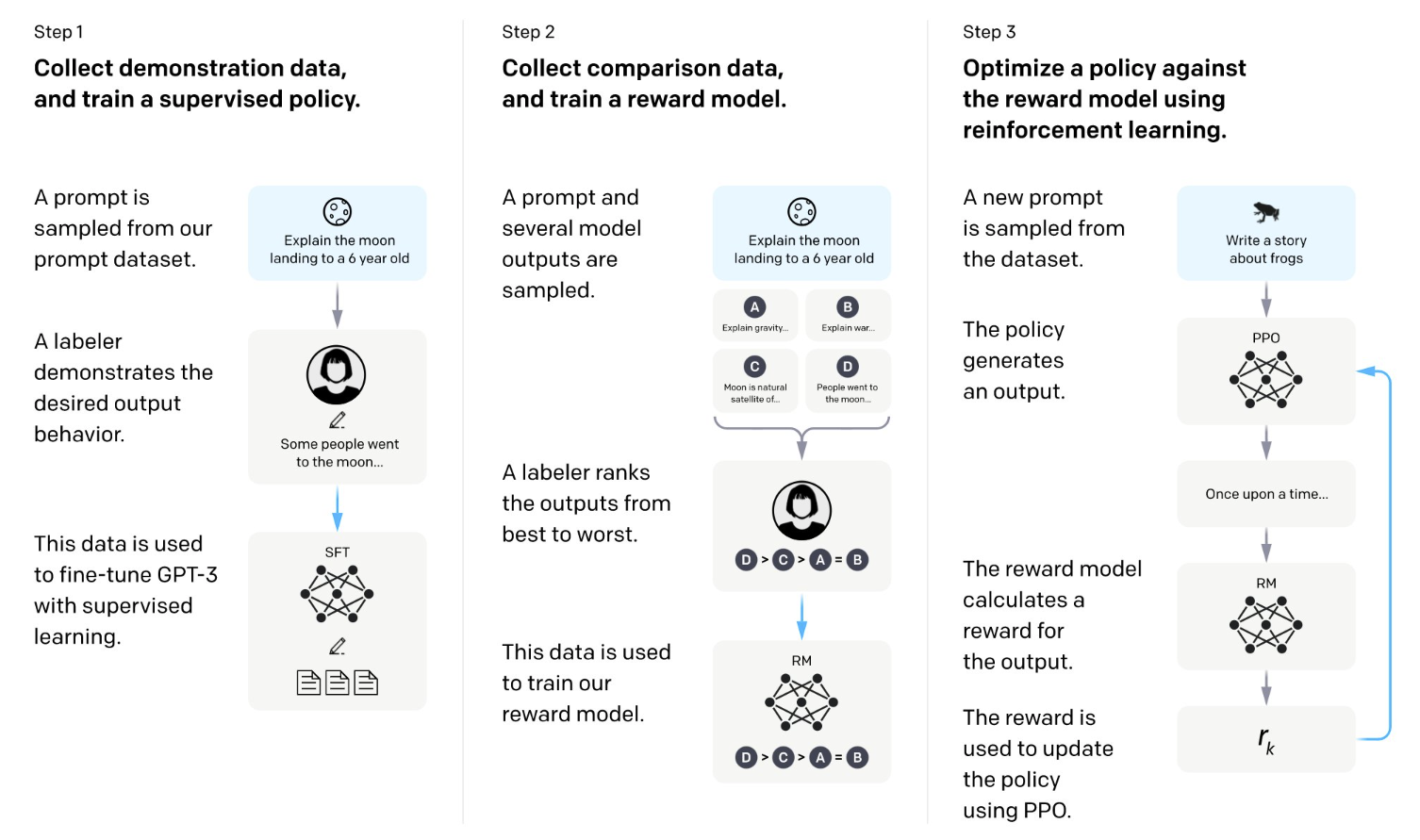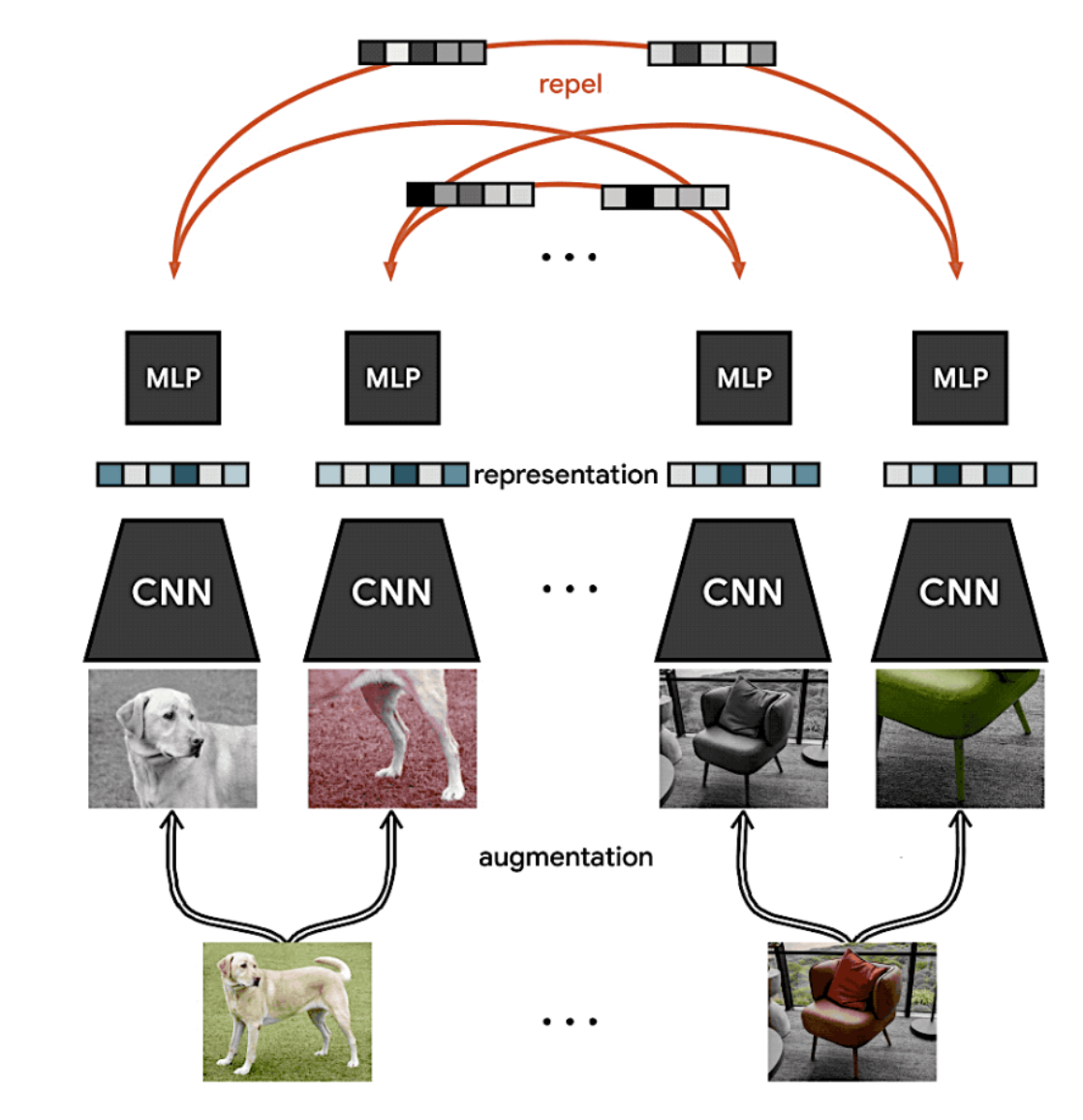
During the second presentation of the Machine Learning reading group, Hrishikesh covered the topic of Contrastive Self-Supervised Learning in the realm of computer vision.
Self-Supervised Learning (SSL) has gained popularity due to its ability to generate high-quality features from data that lacks labels. These methods involve tasks known as pretext tasks, such as predicting image rotation, solving jigsaw puzzles, and others.
In his presentation, Hrishikesh also discussed how to assess the effectiveness of SSL techniques. He emphasised that achieving a perfect score on the pretext task isn’t essential for evaluation; rather, the focus is on evaluating the features’ performance in downstream tasks.
A widely used approach within SSL is Contrastive Learning (CL). The main goal of CL is to bring the embeddings of similar or positive samples, like an image of a cat and its rotated version, closer together in the embedding space. At the same time, CL aims to push apart the embeddings of dissimilar or negative samples, such as an image of a dog. Two prominent CL methods were covered in the talk: (1) SimCLR and (2) MoCo.
Furthermore, Hrishikesh delved into the application of CL in multi-modal scenarios, using the example of CLIP. CLIP was trained using CL on pairs of images and corresponding texts, and it has demonstrated strong performance in zero-shot capabilities.
To wrap up the presentation, Hrishikesh outlined potential future directions for Contrastive Learning. The key questions revolve around how to implement CL in diverse contexts like time-series and graphs, which differ significantly from images.
 LLMs Reading Group Series: LLMs and Their Applications
LLMs Reading Group Series: LLMs and Their Applications