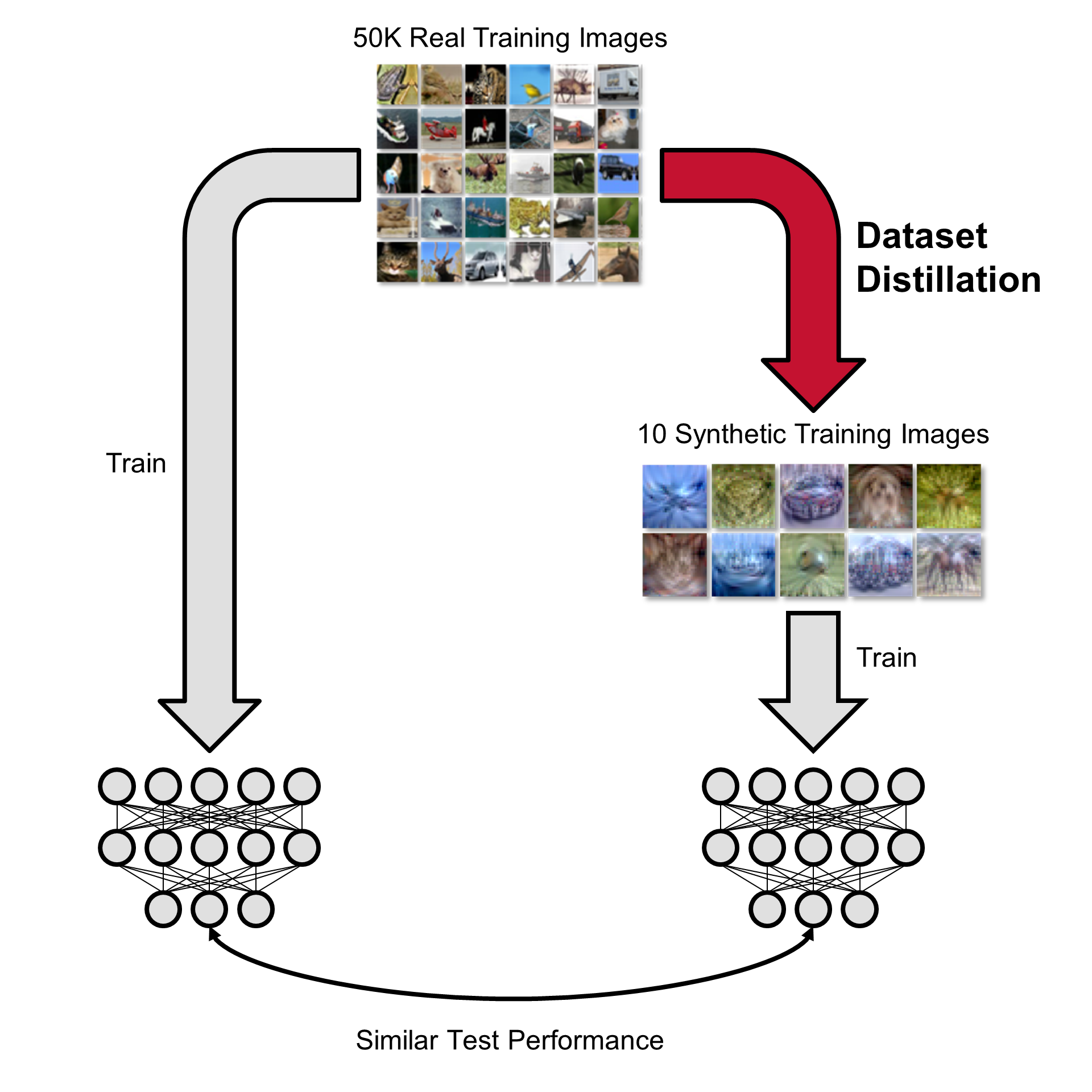
In the first ML reading group, Dr. Junliang Yu introduced data distillation (a.k.a. dataset distillation). Data Distillation aims to generate a more compact and representative dataset from a larger, more complex one. By distilling the data, models can often achieve similar performance with less resource-intensive training processes. It is related to knowledge distillation but different. Compared to similar concepts such as core-set construction, data distillation create new data based on the knowledge in the original one while core-set construction pick out important samples from the original dataset.
Data distillation can be modeled as a bi-level optimization problem. But it is often time-consuming to solve it. Two most commonly used and more efficient solutions are distribution matching and gradient matching.
Data distillation can apply to a lot of domains and situations. Different types of data such as image, text, graph and interaction data can be distilled. The distilled dataset can be used in continual learning, neural architecture search, on-device machine learning, generating poisoning data, etc.
Data distillation faces the following challenges:
- What if multiple variables are required to learn? E.g. node features and adjacency matrix
- What if the data to be distilled is discrete?
- How to avoid that the distilled dataset only learns the dominant pattern in the original dataset?
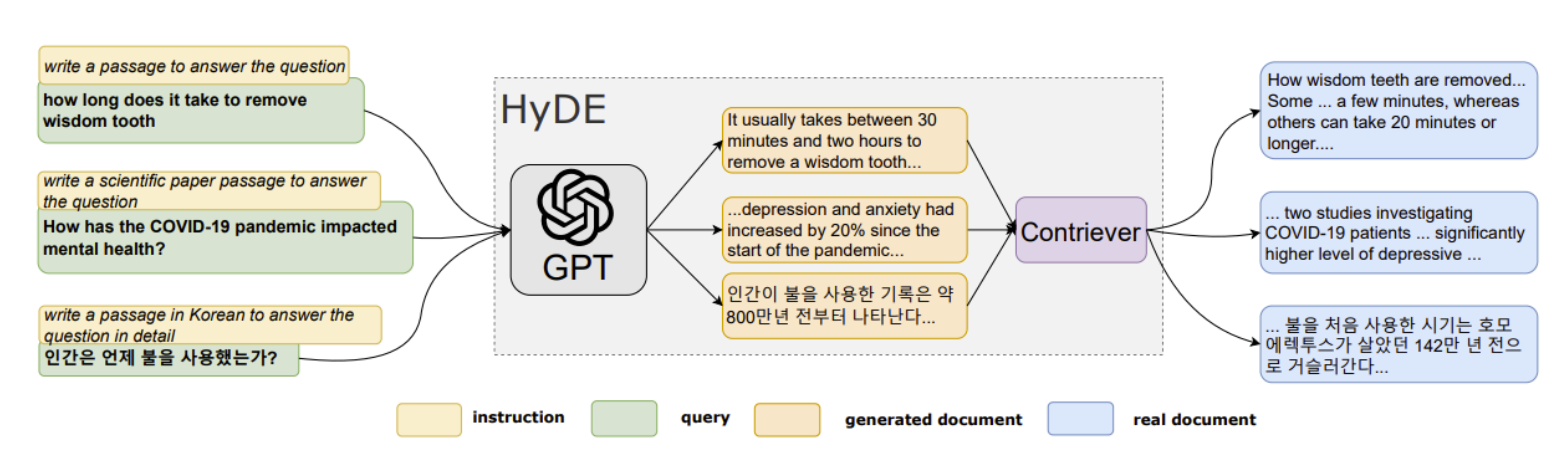 LLMs Reading Group Series: Language Models for Information Retrieval
LLMs Reading Group Series: Language Models for Information Retrieval