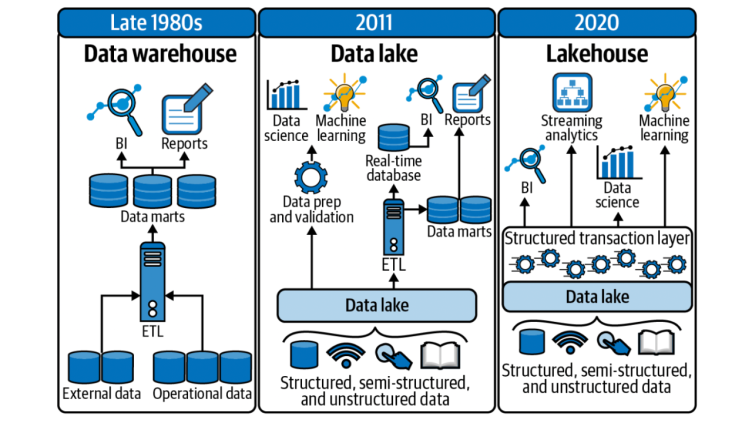
The growing demands of the 5V’s of big data have rendered traditional data warehouse architecture insufficient, leading to the emergence of the data lakehouse as a new architectural design. This cloud-native open-source data architecture supports machine learning and data science while addressing issues associated with traditional data warehouses (e.g., data staleness, reliability, the total cost of ownership, data lock-in, and limited use-case support). The underlying open file formats like Parquet and Avro and data optimisation strategies in data lakehouses can provide organisations with a competitive advantage in data governance, data analytics and data science. Therefore, it is worthwhile for organisations to consider this architecture to stay ahead in the data-driven business.
One might simply say,
Data Lake + Data Warehouse = Data Lakehouse
The data warehouse and data lake architectures significantly differ in design, data types, and usage. A data warehouse is designed to store refined, structured, and relational data with a schema designed at the beginning. It is used for business reporting, visualizations, and business intelligence purposes. Data warehouses collect similar data from multiple resources, and the data is stored in a structured format. In contrast, a data lake architecture is designed to store unstructured, unrefined, and non-relational data with a schema designed at the end. It is primarily used for data science and advanced analytics for machine learning and AI, as it allows the connection of various types of data from various sources. Data lakes can handle data in its native format, allowing for greater flexibility and scalability in the data processing.
Since the focus of this article is on high-performance data science and data governance capabilities, in comparison of data warehouse and data lake, the data lake would be the desirable option. However, we can still highlight certain shortcomings of data lake architectures in comparison to data warehouses that possess desired capabilities.
The both data lake and data lakehouses support high-performance column oriented data formats of ORC and Parquet. These formats allow for efficient data storage, compression, and retrieval. However, there are significant differences between the two architectures:
- Optimised for Machine Learning and Data Analysis: The open and flexible architecture of data lakehouse, which uses formats such as Parquet and Avro, makes it easy to integrate with existing data transformation tools and workflows (e.g., pandas, MLLib, TensorFlow, etc.). It offers efficient access to raw data to build and test machine learning models while supporting SQL queries.
- State-of-the-Art Performance: Data lakehouse’s columnar storage using Parquet enables easy partitioning and compression, resulting in faster data retrieval. Its architecture, utilizing technologies like Spark, supports high-speed processing for both batch and real-time data. Additionally, indexing and caching features further improve query performance and reduce latency.
The one major factor of these differences is the data lakehouses’ special row-oriented data format names Avro. Following is the performance and capabilities comparison of ORC, Parquet, Avro, and other popular file formats.

Source: https://api.semanticscholar.org/CorpusID:70247543
Data lakehouse architectures can achieve ACID compliance (atomic, consistent, isolated, and durable) in the presence of concurrent readers and writers by leveraging file formats like ORC, Parquet, and Avro. ORC and Parquet use a columnar storage format, allowing efficient access and modification of specific columns while maintaining data integrity through metadata files. Meanwhile, Avro is a popular data serialization format that can be used to define the data structure stored in a columnar format, such as Parquet or ORC, enabling more efficient data storage and retrieval. Avro can provide a unified schema for structured and unstructured data, allowing for easier querying and analysis. Avro also supports schema evolution, meaning that changes to the schema can be made over time without breaking existing data pipelines or requiring full data migration. Avro enables this flexibility by storing data in raw form while supporting parallel processing. This assures ACID compliance and provides the scalability and flexibility for modern data processing and analytics workflows.
Data lakehouses can significantly benefit machine learning workflows by leveraging their unique architecture. Many machine learning and deep learning libraries (e.g., TensorFlow, MLLibs, Spark, etc.), can already read data lake file formats like Parquet. Integrating these libraries with a lakehouse can be as simple as querying the metadata layer to determine which Parquet files are part of a table and then passing them to the library. By the way, lakehouse systems also typically support Data-frame APIs (e.g., Pandas, PyArrow, Dask, etc.) which can provide even greater optimisation opportunities. Data-frames offer a table abstraction with various transformation operators, many of which map to relational algebra. Systems like Spark SQL allow users to declare these transformations lazily, so they are evaluated only when needed. These APIs can leverage optimisation by caching and vectorising, and accelerate machine learning workflows by pipelining.
The other advantage of data lakehouse is its ACID compliance, which complements data governance and privacy regulations (e.g., Master data management (MDM), GDPR) by providing a reliable and efficient way of record-level updates and deletes. For example, AICD is an important attribute for satisfying GDPR’s person’s right to be forgotten, which requires organisations to permanently delete an individual’s personal information upon request. In this perspective, Parquet’s columnar storage format, used in data lakes, will not comply with ACID due to its design as an append-only format, making it challenging to modify existing data without rewriting the entire file. In contrast, Avro is a data serialisation format that brings ACID capability to data lakehouses by providing a schema registry that enforces consistency and version control.
The data lakehouse architecture differs from traditional data lake and warehouse systems because it includes metadata, caching, and indexing layers on top of the data storage. These layers are crucial for enhancing the performance, usability, and accessibility of the underlying data storage. The effectiveness of the data lakehouse architecture depends on how these layers are implemented, which is an optimisation task. By doing so, organisations can derive more value and insights from big data.
From the commercial perspective, Delta Lake, Iceberg, and Hudi are three popular data lakehouse technologies that offer various benefits for storing and processing data. Delta Lake is an open-source storage layer that provides ACID transactions and versioning for data stored in cloud storage or Hadoop Distributed File System (HDFS). Delta Lake also offers schema enforcement, which ensures that data conforms to a predefined schema, and schema evolution, which enables changes to the schema over time. Delta Lake uses the Parquet format for storage, which provides columnar storage and efficient compression. Delta Lake’s strengths lie in its transactional capabilities and data consistency, making it a suitable choice for mission-critical applications that require strict data integrity.
Iceberg is another open-source data lakehouse technology that provides a table format for data stored in cloud storage or HDFS. Iceberg supports schema evolution, allowing users to add or remove columns without requiring a full data rewrite. It also enables users to query data at specific points in time. Iceberg uses an append-only design, ensuring data immutability, and supports various file formats, including Parquet, ORC, and Avro. Iceberg is well-suited for large-scale data processing applications that require versioning and time-travel capabilities.
Hudi (Hadoop Upsert/Delete/Increment) is an open-source data lakehouse technology that provides record-level inserts, updates, and deletes for data stored in cloud storage or HDFS. Hudi uses a copy-on-write storage model, which ensures that data is immutable and versioned. It also supports schema evolution and provides efficient upserts, allowing users to merge new data with existing data. Hudi uses the Avro format for storage, which provides efficient serialization and deserialization. Hudi is suitable for use cases that require efficient data ingestion and support for record-level updates and delete.
Hive LLAP (Low Latency Analytical Processing) also can be used as a data lakehouse by storing data in a cloud-based or Hadoop-based storage system and creating tables in Hive that map to the data. It supports ACID transactions and various file formats (e.g., Parquet, ORC, and Avro), provides low-latency access to data by caching frequently accessed data in memory, and supports a wide range of SQL operations. Hive LLAP stores metadata in a metadata store such as Apache Atlas, and uses indexing techniques like Bloom filters, Bitmap indexes, and Columnar indexes to accelerate query performance by avoiding full table scans. The tool’s caching layer uses techniques like pre-fetching and eviction policies to optimize the caching process, and provides an option to persist the cached data on disk to avoid cache misses and reduce query latency.
Conclusion
A data lakehouse integrates data lake storage with data warehousing functionality, offering several advantages over traditional data lake and warehouse systems. By implementing a structured transaction layer on top of the data lake, the data lakehouse ensures ACID compliance while allowing raw-based data storage with a column-based data structure, which is desirable for machine learning and regulatory compliance. Despite the limitations in cloud-native open-source data formats, lakehouse systems can achieve competitive performance through optimisations such as caching, indexing, vectorising and pipelining.
Original article:
https://www.linkedin.com/pulse/lakehouse-convergence-data-warehousing-science-dr-mahendra/?trackingId=Xkd2bdHg%2FGeifEXXyCgFDQ%3D%3D
 Reading Group: How to Develop and Use AI in a Responsible Way
Reading Group: How to Develop and Use AI in a Responsible Way