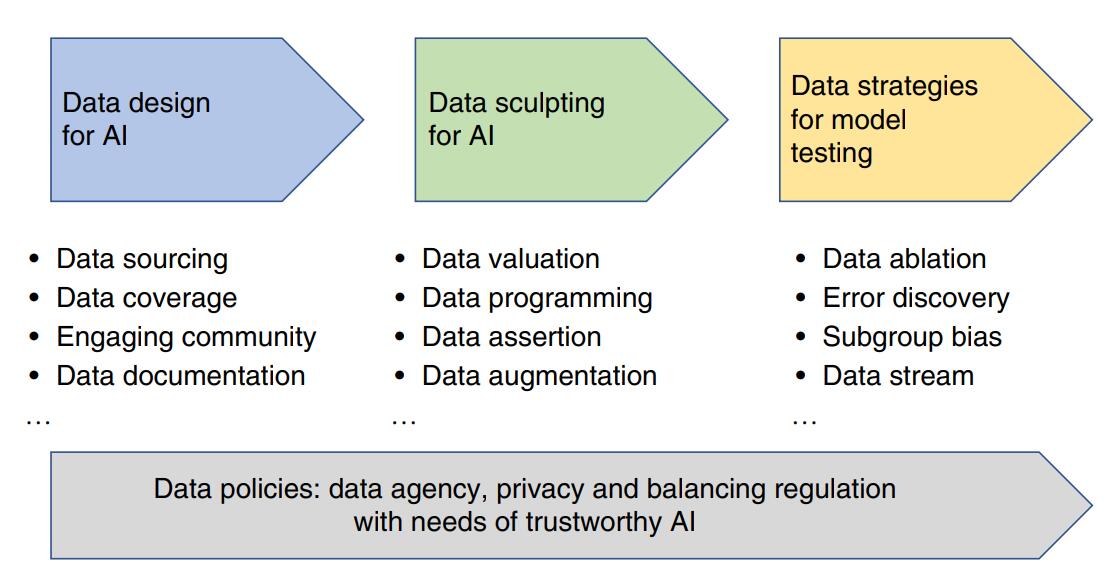
As artificial intelligence (AI) transitions from research to deployment, creating the appropriate datasets and data pipelines to develop and evaluate AI models is increasingly the biggest challenge. Automated AI model builders that are publicly available can now achieve top performance in many applications. In contrast, the design and sculpting of the data used to develop AI often rely on bespoke manual work, and they critically affect the trustworthiness of the model. This Perspective discusses key considerations for each stage of the data-for-AI pipeline—starting from data design to data sculpting (for example, cleaning, valuation and annotation) and data evaluation—to make AI more reliable. We highlight technical advances that help to make the data-for-AI pipeline more scalable and rigorous. Furthermore, we discuss how recent data regulations and policies can impact AI.
Authors: Weixin Liang, Girmaw Abebe Tadesse, Daniel Ho, L. Fei-Fei, Matei Zaharia, Ce Zhang & James Zou
Journal: Nature Machine Intelligence
 A Snapshot of the Frontiers of Fairness in Machine Learning
A Snapshot of the Frontiers of Fairness in Machine Learning