
Recently, the field has been greatly impressed and inspired by OpenAI’s ChatGPT. It is undoubtedly clever, capable, and very fun to talk to. Its multi-faceted abilities are significantly beyond many NLP researchers’ and practitioners’ expectations based on the impression of (not-that-strong) original GPT-3. The natural question is how ChatGPT gets there, and where these fantastic abilities come from. In this post, we try to dissect the emergent abilities and trace them to their sources, hoping to give a comprehensive roadmap about how the GPT-3.5 model family, along with related large language models, evolved to their current forms.
We hope this post can promote the transparency of large language models and serve as the roadmap for the community’s ongoing efforts of reproducing GPT-3.5.
To readers:
- leave a message if you feel any part of this article is not supported by strong enough evidence. You can directly comment on the corresponding part/ email me/ comment on my twitter to request clarification.
- Please do contact me if you want to translate this article into other languages.
Table of Content
Many years later, as he faced the firing squad, Colonel Aureliano Buendía was to remember that distant afternoon when his father took him to discover ice. — One Hundred Years of Solitude by Gabriel García Márquez.
1. Initial 2020 GPT-3, large-scale pretraining
There are three important abilities that the initial GPT-3 exhibit:
- Language generation: to follow a prompt and then generate a completion of the given prompt. Today, this might be the most ubiquitous way of human-LM interaction.
- In-context learning: to follow a few examples of a given task and then generate the solution for a new test case. It is interesting to note that, although being a language model, the original GPT-3 paper barely talks about “language modeling” — the authors devoted their writing efforts to their visions of in-context learning, which is the real focus of GPT-3.
- World knowledge: including factual knowledge and commonsense.
Where do these abilities come from?
Generally, the above three abilities should come from large-scale pretraining — to pretrain the 175B parameters model on 300B tokens (60% 2016 - 2019 C4 + 22% WebText2 + 16% Books + 3% Wikipedia). Where:
- The language generation ability comes from the language modeling training objective.
- The world knowledge comes from the 300B token training corpora (or where else it could be).
- The 175B model size is for storing knowledge, which is further evidenced by Liang et al. (2022), who conclude that the performance on tasks requiring knowledge correlates with model size.
- The source of the in-context learning ability, as well as its generalization behavior, is still elusive. Intuitively, this ability may come from the fact that data points of the same task are ordered sequentially in the same batch during pretraining. Yet there is little study on why language model pretraining induces in-context learning, and why in-context learning behaves so differently than fine-tuning.
A curious question is how strong the initial GPT-3 is.
It is rather challenging to determine whether the initial GPT-3 (davinci in OpenAI API) is “strong” or “weak.” On the one hand, it responds to certain queries reasonably and achieves OK-ish performance on many benchmarks; on the other, it underperforms small models like T5 on many tasks (see its original paper). It is also very hard to say the initial GPT-3 is “smart” in today’s (= Dec 2022) ChatGPT standard. The sharp comparison of initial GPT-3’s ability v.s. today’s standard is replayed by Meta’s OPT model, which is viewed as “just bad” by many who have tested OPT (compared to text-davinci-002). Nevertheless, OPT might be a good enough open-source approximation to the initial GPT-3 (according to the OPT paper and Stanford’s HELM evaluation).
Although the initial GPT-3 might be superficially weak, it turns out later that these abilities serve as very important foundations of all the emergent abilities unlocked later by training on code, instruction tuning, and reinforcement learning with human feedback (RLHF).
2. From 2020 GPT-3 to 2022 ChatGPT
Starting from the initial GPT-3, to show how OpenAI arrives at ChatGPT, we look at the GPT-3.5 evolution tree:
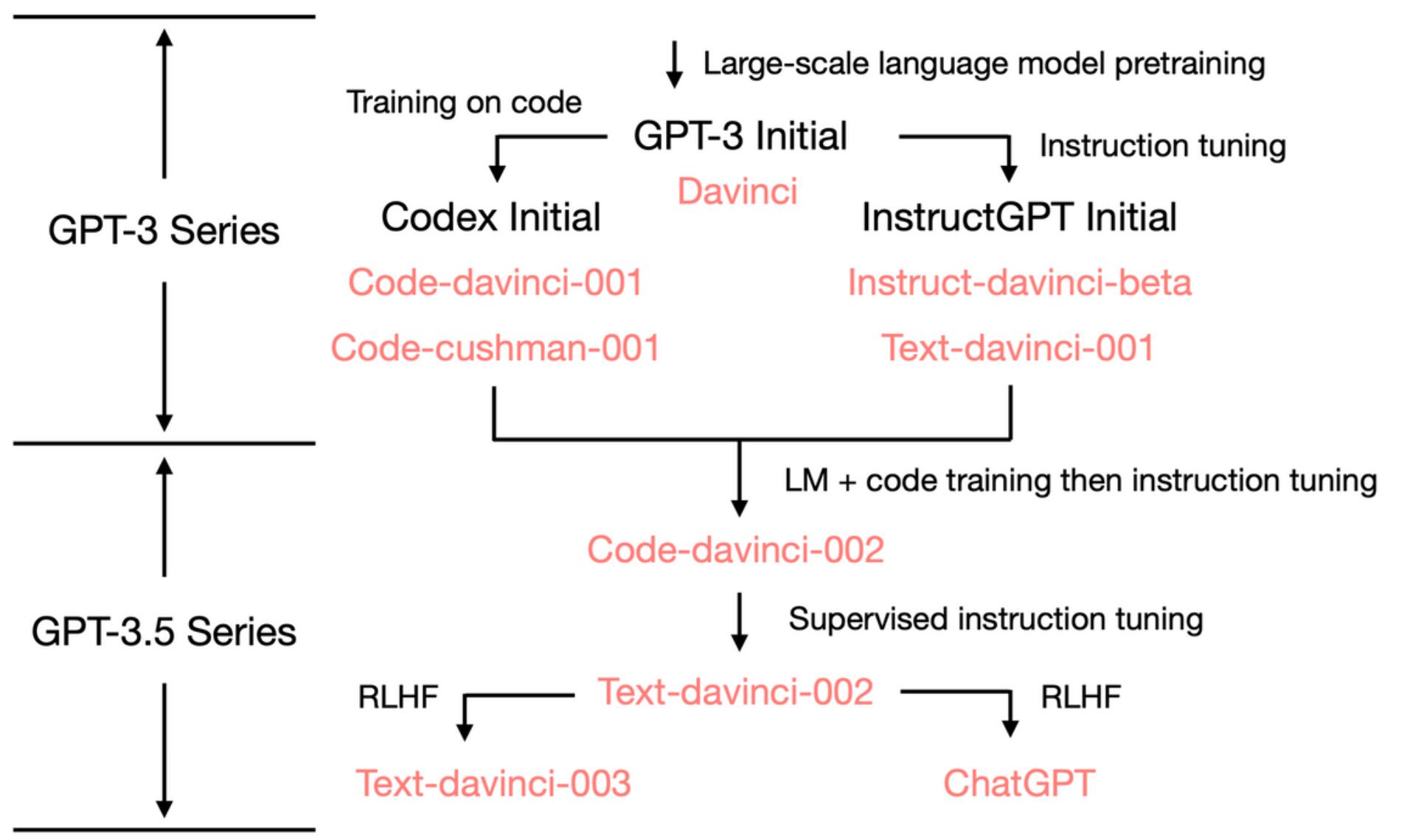
In Jul 2020. OpenAI released the initial GPT-3 paper with the davinci model index, and it started to evolve. In Jul 2021, the Codex paper was released, where the initial Codex is fine-tuned from a (presumably internal) 12B GPT-3 variant. Later this 12B model evolved to be the code-cushman-001 in OpenAI API. In Mar 2022, OpenAI released the instruction tuning paper, and its supervised tuning part corresponds to the davinci-instruct-beta and text-davinci-001. At some point in Apr-Jul 2022, OpenAI started to beta test the code-davinci-002 model, also calling it Codex. Then text-davinci-002, text-davinci-003, and ChatGPT are all instruction-tuned from code-davinci-002. See OpenAI’s Model Index document for more details.
Although called Codex, code-davinci-002 is probably the most capable GPT-3.5 variant for natural language (better than text-davinci-002 and 003). It is very likely code-davinci-002 is trained on both text and code, then tuned on instructions (will explain below). Then text-davinci-002, released in May-Jun 2022, is a supervised instruction-tuned model based on code-davinci-002. It is very likely that the instruction tuning on text-davinci-002 decreased the model’s in-context learning ability but increased the model’s zero-shot ability (will explain below). Then text-davinci-003 and ChatGPT, both released in Nov 2022, are two different variants of instruction-tuned models using Reinforcement Learning with Human Feedback. text-davinci-003 recovered (but still worse than code-davinci-002) some in-context learning ability that is lost in text-davinci-002 (presumably because it tunes the model with LM mix-in) and further improved zero-shot ability (thanks to RLHF). On the other hand, ChatGPT seems to have sacrificed nearly all of its in-context learning ability to trade for the ability to model dialog context.
In summary, during 2020-2021, before code-davinci-002, substantial efforts have been devoted to enhancing GPT-3 with code training and instruction tuning. When they have reached code-davinci-002, all the abilities are there. It is likely that the following-up instruction-tuning, either supervised or RLHF, does the following things (will detail later):
- Instruction tuning does not inject new abilities into the model — all abilities are already there. Instead, instruction tuning unlocks/ elicit these abilities. This is mostly because the instruction tuning data is orders or magnitudes less than the pretraining data.
- Instruction tuning adjusts skillsets of GPT-3.5 towards different branches. Some are better at in-context learning like text-davinci-003, some are better at dialog like ChatGPT.
- Instruction tuning trade performance for alignment with humans. The OpenAI authors call it “alignment tax” in their instruction tuning paper. Also, many papers have reported code-davinci-002 achieves the best performance on benchmarks. Instruction tuning on code-davinci-002 gives the subsequent models alignments like zero-shot question answering, generating safe and impartial dialog responses, and rejecting questions beyond its knowledge scope.
3. Code-Davinci-002 & Text-Davinci-002, training on code, tuning on instructions
Before code-davinci-002 and text-davinci-002, there are two intermediate models, namely davinci-instruct-beta and text-davinci-001. Both are worse than the two -002 models in many aspects (e.g., text-davinci-001 cannot do chain-of-thought reasoning). So we focus on the -002 models in this section.
3.1. The sources of complex reasoning ability and the ability to generalize to new tasks
Now let’s look at code-davinci-002 and text-davinci-002, the two first GPT3.5 models, one for code and the other for text. There are four important abilities they exhibit that differentiate them from the initial GPT-3
- Responding to human instruction: previously, the outputs of GPT-3 were mostly high-frequency prompt-completion patterns within the training set. Now the model generates reasonable answers to the prompt, rather than related but useless sentences.
- Generalization to unseen tasks: when the number of instructions used for tuning the model is beyond a certain scale, the model can automatically generate completions for new instructions that are not in the training set. This ability is crucial for deployment, as users with always come up with new prompts.
- Code generation and code understanding: obviously, because the model is trained on code.
- Complex reasoning with chain-of-thought: previously, the model could not do tasks requiring multi-step reasoning with chain-of-thought. codex-davinci-002 and text-davinci-002 are the two initial models exhibiting chain-of-thought reasoning ability.
- The reason that chain-of-thought is important is because that CoT is likely to be the key to unlock the emergent abilities and transcend scaling laws. See the previous blog post.
Where do these abilities come from?
Compared to the previous models, the two major differences are instruction tuning and training on code. Specifically
- The ability to respond to human instructions is a direct product of instruction tuning.
- The ability of generalization to unseen instructions is a free lunch given by scaling types of instructions, as is further evidenced by T0, Flan, and FlanPaLM papers
- The ability of complex reasoning with chain-of-thought is likely to be a magical side product of training on code:
- The initial GPT-3 is not trained on code, and it cannot do chain-of-thought
- The text-davinci-001, although being instruction tuned,
cannot do CoT(corrected by Denny Zhou) can do CoT but the performance is significantly worse, as is reported by the first version of the CoT paper — so instruction tuning may not be the reason for CoT. This leaves training on code to be be the number one suspect. - PaLM has 5% code training data, and it can do chain-of-thought.
- The code data in the codex paper is 159G, approximately 28% of the initial GPT-3 570G training data. code-davinci-002 and its subsequent variants can do chain-of-thought.
- Copilot, supposedly powered by a 12B model, can also do CoT.
- On the HELM evaluation, a massive-scale evaluation performed by Liang et al. (2022), the authors also found that models trained on/ for code has strong language reasoning abilities, including the 12B-sized code-cushman-001.
- Code-davinci-002 has higher CoT upper bound on other models: Our work at AI2 also shows that when equipped with complex chains of thought, Code-davinci-002 is the SOTA model on important math benchmarks like GSM8K.
- As an intuition, think about how procedure-oriented programming is similar to solving tasks step by step, and how object-oriented programming is similar to decomposing complex tasks into simpler ones.
- All the above observations are correlations between code and reasoning ability/ CoT. Such a correlation between code and reasoning ability/ CoT is very intriguing to the community and not well-understood. However, there is still no hard evidence showing training on code is absolutely the reason for CoT and complex reasoning. The source of CoT is still an open research problem.
- Additionally, long-term dependency might also be a nice side effect of training on code. As is pointed out by Peter Liu. “Next token prediction for language is usually very local, whereas code often requires longer dependencies to do things like close brackets or refer to distant defs”. I would further add: code may also give the model of encoding hierarchy due to inheritance in object-oriented programming. We leave the test of this hypothesis to future work.
There are certain detailed differences we would like to note:
- text-davinci-002 v.s. code-davinci-002
- Code-davinci-002 is the base model, text-davinci-002 is the product of fine-tuning code-davinci-002 on (see documentation): (a). Human-annotated instructions and completions; (b). Self-generated completions chosen by human-annotators
- Code-davinci-002 is better at in-context learning (when there are few task demonstrations); text-davinci-002 is better at zero-shot task completion (no demonstrations). In this sense, text-davinci-002 is more aligned with humans (because coming up with a task demonstration can be troublesome).
- It is unlikely that OpenAI intentionally trades in-context learning ability for zero-shot ability — this tradeoff is more like a side effect of supervised instruction tuning (the alignment tax).
- 001 models (code-cushman-001 and text-davinci-001) v.s. 002 models (code-davinci-002 and text-davinci-002)
- The 001 models might be trained for code-
onlymainly / text-onlymainly purpose (but still a mixture of text and code); the 002 models combines code tuning and instruction tuning - The first model after the combination is likely to be code-davinci-002. The supporting facts are that code-cushman-001 can do reasoning but not well on pure text, text-davinci-001 can do pure text but not well on reasoning. code-davinci-002 can do both.
- The 001 models might be trained for code-
3.2. Are these abilities already there after pretraining or later injected by fine-tuning?
At this stage, we already have identified the crucial role of instruction tuning and training on code. One important question is how to further disentangle the effects of code training and instruction tuning. Specifically:
Are the above three abilities already there in the initial GPT-3 but triggered/ unlocked by instruction and code training or not in the initial GPT-3 but injected by instruction and code training?
If the answer is already in the initial GPT-3, then these abilities should also be in OPT might be partially in OPT. So to reproduce these abilities, one can directly instruction-and-code-tune OPT [update Dec 23: Meta have already done it]. Yet it is also likely that code-davinci-002 is NOT based on the initial GPT-3 davinci, but some other models with unknown training procedures. If this is the case, tuning OPT might not be an option for reproduction, and the community need to figure out further what kind of model OpenAI has trained as the base model for code-davinci-002.
We have the following hypothesis and evidence:
- The base model for code-davinci-002 is highly likely not be the initial GPT-3 davinci model. Below are the evidence/ indicators
- The initial GPT-3 is trained on
C4Common Crawl 2016 - 2019. code-davinci-002 training set ends in 2021. So it is possible that code-davinci-002 is trained on the 2019-2021 version of C4. - The initial GPT-3 has a context window 2048. code-davinci-002 has a context window
40968192. GPT series use absolute positional embedding, and directly extrapolating absolute positional embedding beyond training is challenging and can seriously harm the model performance (see Press et al., 2022). If code-davinci-002 is based on the initial GPT-3, how did OpenAI expand the context window? - There are recent works using sparse mixture-of-expert to substantially scale up the model parameter with constant computational cost, like Switch Transformers. If GPT-3.5 uses this technique, it can be significantly larger than GPT-3.
- The initial GPT-3 is trained on
- On the other hand, either the base model is the initial GPT-3 or some later trained model, the ability to follow instruction and zero-shot generalization may already be in the base model and is later unlocked (not injected) by instruction tuning
- This is primarily because the instruction data reported by OpenAI’s paper is only 77K, which is orders of magnitudes less than the pretraining data.
- The contrast of dataset size is further evidenced by other instruction tuning papers, e.g., Chung et al. (2022) where instruction tuning of Flan-PaLM is just 0.4% compute of pretraining. Instruction data is generally significantly less than pretraining data.
- Yet complex reasoning may be injected from code data during the pretraining stage
- The scale of code data is different than the above instruction tuning case. Here the amount of code data is large enough to take a nontrivial portion of the training data (e.g., PaLM has 8% code training data)
- As mentioned above, the reasoning/ chain of thought ability in text-davinci-001, the model before code-davinci-002, presumably not tuned on code, is very low, as is reported in the first version of the chain-of-thought paper, sometimes even worse than a smaller code-cushman-001.
- The best way to disentangle the effects of code tuning and instruction tuning might be to compare code-cushman-001, T5, and FlanT5
- Because they have similar size (11B and 12B), and similar training data (C4), and the only difference are code/ instruction tuning.
- There are no such comparisons yet. We leave this to future research.
4. text-davinci-003 & ChatGPT, the power of Reinforcement Learning from Human Feedback (RLHF)
At the current stage (Dec 2022), there are few strict statistically clear comparisons between text-davinci-002, text-davinci-003 and ChatGPT, mostly because
- text-davinci-003 and ChatGPT have only been released less than a month when this article is written.
- ChatGPT cannot be called by OpenAI API, so it is troublesome to test it on standard benchmarks.
So the comparison between these models is more based on the collective experiences of the community (not very statistically strict). Yet we do believe certain initial descriptive comparisons still shed light on the underlying model mechanisms.
We first note that the following comparisons between text-davinci-002 v.s. text-davinci-003 v.s. ChatGPT:
- All three models are instruction tuned.
- text-davinci-002 is a supervised instruction-tuned model
- text-davinci-003 and ChatGPT are instruction tuned with Reinforcement Learning with Human Feedback (RLHF). This is the most prominent difference.
This means that most of the new model behaviors are the product of RLHF.
So let’s look at the abilities triggered by RLHF:
- Informative responses: text-davinci-003’s generation is usually longer than text-davinci-002. ChatGPT’s response is even more verbose such that one has to explicitly ask, “answer me in one sentence” to make it concise. This is a direct product of RLHF.
- Impartial responses: ChatGPT often gives very balanced responses on events involving interests from multiple entities, such as political events. This is also a product of RLHF
- Rejecting improper questions.This is the combination of a content filter and the model’s own ability induced by RLHF.
- Rejecting questions outside its knowledge scope: for example, rejecting new events that happened after Jun 2021. This is the most amazing part of RLHF because it enables the model to implicitly and automatically classify which information is within its knowledge and which is not.
There are two important things to notice:
- All the abilities are intrinsically within the model, not injected by RLHF. RLHF triggers/unlock these abilities to emerge. This is again because of the data size, as the RLHF tuning takes significantly less portion of computing compared to pretraining.
- Knowing what it does not know is not achieved by writing rules; it is also unlocked by RLHF. This is a very surprising finding, as the original goal of RLHF is for alignment, which is more related to generating safe responses than knowing what the model does not know.
What happens behind the scene might be:
- ChatGPT: Trade in-context learning for dialog history modeling. This is an empirical observation as ChatGPT seems not to be strongly affected by in-context demonstrations as text-davinci-003 does.
- Text-davinci-003: recover the in-context learning ability sacrificed by text-davinci-002 and improve the zero-shot ability.
We are not sure if this is also a side product of RLHF or something else.According to the instructGPT paper, this is from the LM-mixing during the RL tuning stage (not RLHF itself).
5. Summary of Current Understanding of GPT-3.5’s Evolution
So far, we have scrutinized all the abilities that emerged along the evolution tree. Below is a table summarizing the path:
Ability | OpenAI Model | Training Method | OpenAI API | OpenAI Paper | Open Source Approximate |
GPT-3 Series | |||||
Generation
+ World Knowledge
+ In-context Learning | GPT-3 Initial
**Many abilities already within this model, although superficially weak | Language Modeling | Davinci | GPT 3 Paper | Meta OPT |
+ Follow Human Instruction
+ generalize to unseen task | Instruct-GPT initial | Instruction Tuning | Davinci-Instruct-Beta | Instruct-GPT paper | T0 paper
Google FLAN paper |
+ Code Understanding
+ Code Generation | Codex initial | Training on Code | Code-Cushman-001 | Codex Paper | Salesforce CodeGen |
GPT-3.5 Series | |||||
++ Code Understandning
++ Code Generation
++ Complex Reasoning / Chain of Thought (why?)
+ long-term dependency (probably) | Current Codex
**Strongest model in GPT3.5 Series | Training on text + code
Tuning on instructions | Code-Davinci-002
(currently free. current = Dec. 2022) | Codex Paper | ?? |
++ Follow Human Instruction
- In-context learning
- Reasoning
++ Zero-shot generation | Instruct-GPT supervised
**Trade in-context learning for zero-shot generation | Supervised instruction tuning | Text-Davinci-002 | Instruct-GPT paper, supervised part | T0 paper
Google FLAN paper |
+ Follow human value
+ More detailed generation
+ in-context learning
+ zero-shot generation | Instruct-GPT RLHF
**More aligned than 002, less performance loss | Instruction tuning w. RLHF | Text-Davinci-003 | Instruct-GPT paper, RLHF part
Summarization .w human feedback | DeepMind Sparrow paper
AI2 RL4LMs |
++ Follow human value
++ More detailed generation
++ Reject questions beyond its knowledge (why?)
++ Model dialog context
-- In-context learning | ChatGPT
** Trade in-context learning for dialog history modeling | Tuning on dialog w. RLHF | - | - | DeepMind Sparrow paper
AI2 RL4LMs |
We have concluded:
- The language generation ability + basic world knowledge + in-context learning are from pretraining (
davinci) - The ability to store a large amount of knowledge is from the 175B scale.
- The ability to follow instructions and generalizing to new tasks are from scaling instruction tuning (
davinci-instruct-beta) - The ability to perform complex reasoning is likely to be from training on code (
code-davinci-002) - The ability to generate neutral, objective, safe, and informative answers are from alignment with human. Specifically:
- If supervised tuning, the resulting model is
text-davinci-002 - If RLHF, the resulting model is
text-davinci-003 - Either supervised or RLHF, the models cannot outperform code-davinci-002 on many tasks, which is called the alignment tax.
- If supervised tuning, the resulting model is
- The dialog ability is also from RLHF (
ChatGPT), specifically it tradeoffs in-context learning for:- Modeling dialog history
- Increased informativeness
- Rejecting questions outside the model’s knowledge scope
6. What GPT-3.5 currently cannot do
Although it is a major step in NLP research, GPT-3.5 does not fully contain all the ideal properties envisaged by many NLP researchers (including AI2). Below are certain important properties that GPT-3.5 does not have:
- On-the-fly overwriting the model’s belief: when the model expresses its belief in something, it might be hard to correct it when the belief is wrong:
- One recent example I encountered is that ChatGPT insists that 3599 is a prime number even though it acknowledged that 3599 = 59 * 61. Also, see the fastest marine mammal example on Reddit.
- Yet there seems to be a hierarchy of how strong the belief is. One example is that the model believes the current president of the US is Biden, even if I told it Darth Vader won the 2020 election. Yet if I change the election year to 2024, it believes that the president is Darth Vader in 2026.
- This means that there exists a list of very strong core belief — very strong that cannot be overwrite by any means. It is extremely important to ensure such core belief should be absolutely 100% aligned with human.
- Formal reasoning: the GPT-3.5 series cannot do reasoning within formal, strict systems like math or first-order logic
- In the NLP literature, the word “reasoning” is less well-defined. Yet if we view there is a spectrum of ambiguity like (a) very ambiguous, no reasoning; (b) mixture of logic and ambiguous statements; (c). no ambiguity has to be very rigorous, then,
- The model can do very well on type (b) reasoning with ambiguity; examples include:
- Generating a procedure of how to cook pizza. It is acceptable if there exist ambiguities in the intermediate steps, like using sausage or pineapple. As long as the overall steps are approximately correct, the pizza is eatable (sorry if you are Italian).
- Generating proof sketch of a theorem. Proof sketches are informal step-by-step procedures expressed in language, where the strict derivation of one step can be left unspecified. This is a useful math teaching and thinking tool. As long as the overall steps are approximately correct, the students can fill in the details as homework.
- The model cannot do type (c) reasoning (reasoning does not tolerate ambiguity).
- One example is deriving strict proofs that require no mistakes in intermediate steps.
- Yet whether such reasoning should be done by a language model or a symbolic system is up for discussion. For example, instead of trying hard to make GPT do three digits addition, one might simply call Python.
- Retrieval from the Internet: the GPT-3.5 series cannot directly search the internet (for now)
- Yet there was a WebGPT paper published in Dec 2021. It is likely that this is already tested internally within OpenAI.
- The two important but different abilities of GPT-3.5 are knowledge and reasoning. Generally, it would be ideal if we could offload the knowledge part to the outside retrieval system and let the language model only focus on reasoning. This is because:
- The model’s internal knowledge is always cut off at a certain time. The model always needs up-to-date knowledge to answer up-to-date questions.
- Recall we have discussed that is 175B parameter is heavily used for storing knowledge. If we could offload knowledge to be outside the model, then the model parameter might be significantly reduced such that eventually, it can run on a cellphone (call this crazy here, but ChatGPT is already science fiction enough, who knows what the future will be).
7. Conclusion
In this post, we scrutinize the spectrum of abilities of the GPT-3.5 series and trace back to the sources of all their emergent abilities. The initial GPT-3 model gains its generation ability, world knowledge, and in-context learning from pretraining. Then the instruction tuning branch gains the ability to follow instructions and generalization to unseen tasks. The training on code branch gains the ability of code understanding, and potentially the side product of complex reasoning. Combining the two branches, code-davinci-002 seems to be the most capable GPT-3.5 model with all the powerful abilities. The following supervised instruction tuning and RLHF trades model ability for alignment with humans, i.e., the alignment tax. RLHF enables the model to generate more informative and impartial answers while rejecting questions outside its knowledge scope.
We hope this article can help provide a clear picture of the evaluation of GPT, and stir some discussion about language models, instruction tuning, and code tuning. Most importantly, we hope this article can serve as the roadmap for reproducing GPT-3.5 within the open-source community.
“Because it’s there.” — George Mallory, the pioneer of the Mount Everest expedition
Citation
Cite as:
Fu, Yao; Peng, Hao and Khot, Tushar. (Dec 2022). How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources. Yao Fu’s Notion. https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
Or
@article{fu2022gptroadmap,
title = "How does GPT Obtain its Ability? Tracing Emergent Abilities of Language Models to their Sources",
author = "Fu, Yao; Peng, Hao and Khot, Tushar",
journal = "Yao Fu’s Notion",
year = "2022",
month = "Dec",
url = "[https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1](https://www.notion.so/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1)"
}
Frequently Asked Questions
- Are these claims in this article more like hypothesis or conclusions?
- Complex reasoning is from training on code is a hypothesis we tend to believe
- Generalization on unseen tasks is from scaling instruction tuning is a conclusion from at least 4 papers
- GPT-3.5 is from a large base model than GPT-3 175B is an educated guess.
- All these abilities are there, instruction tuning, either supervised or reinforce, unlocks, but not inject, these abilities is a strong hypothesis, very strong such that it is hard not to believe. Mostly because instruction tuning data are orders of magnitudes less than pretraining data
- Conclusion = many evidences supporting its correctness; Hypothesis = there are positive evidences but not strong enough; Educated guess = no hard evidence but certain factors indicate so
- Why other models like OPT and BLOOM are not so strong?
- OPT probably because training process too unstable
- BLOOM
do not know. Do contact me if you have more commentsProbably did not train with enough steps given their reported numbers (375 A100 for two month cannot train a 176B model to Chinchilla optimal) - Also their portion of English data is significantly smaller than other models
- This further leads to a question: say we want to train bi-/ multi- lingual model, do we want to make it 50% English 50% other languages for balanced abilities, or we should use 90% English then transfer the abilities to other languages (since the amount/ quality of English data is much larger/ better than other languages)?
- Will large language model replace search engine?
- No. LLMs are good for reasoning, not for knowledge. The knowledge within LLMs are unreliable and cannot be verified.
- On the other hand, the knowledge from search engine is orders or magnitude larger than LLM’s internal knowledge, can one can easily verify credibility of search results by checking the source.
- Combining LLMs and search is a good direction. Let search handle knowledge, let LLMs handle reasoning.
Original article:
https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
 Top Python Libraries for Data Visualization (Static and Interactive Visualization)
Top Python Libraries for Data Visualization (Static and Interactive Visualization)