During the second presentation of the LLM reading group, Hrishikesh provided an overview of popular LLM architectures, specifically focusing on BERT, GPT, and T5.
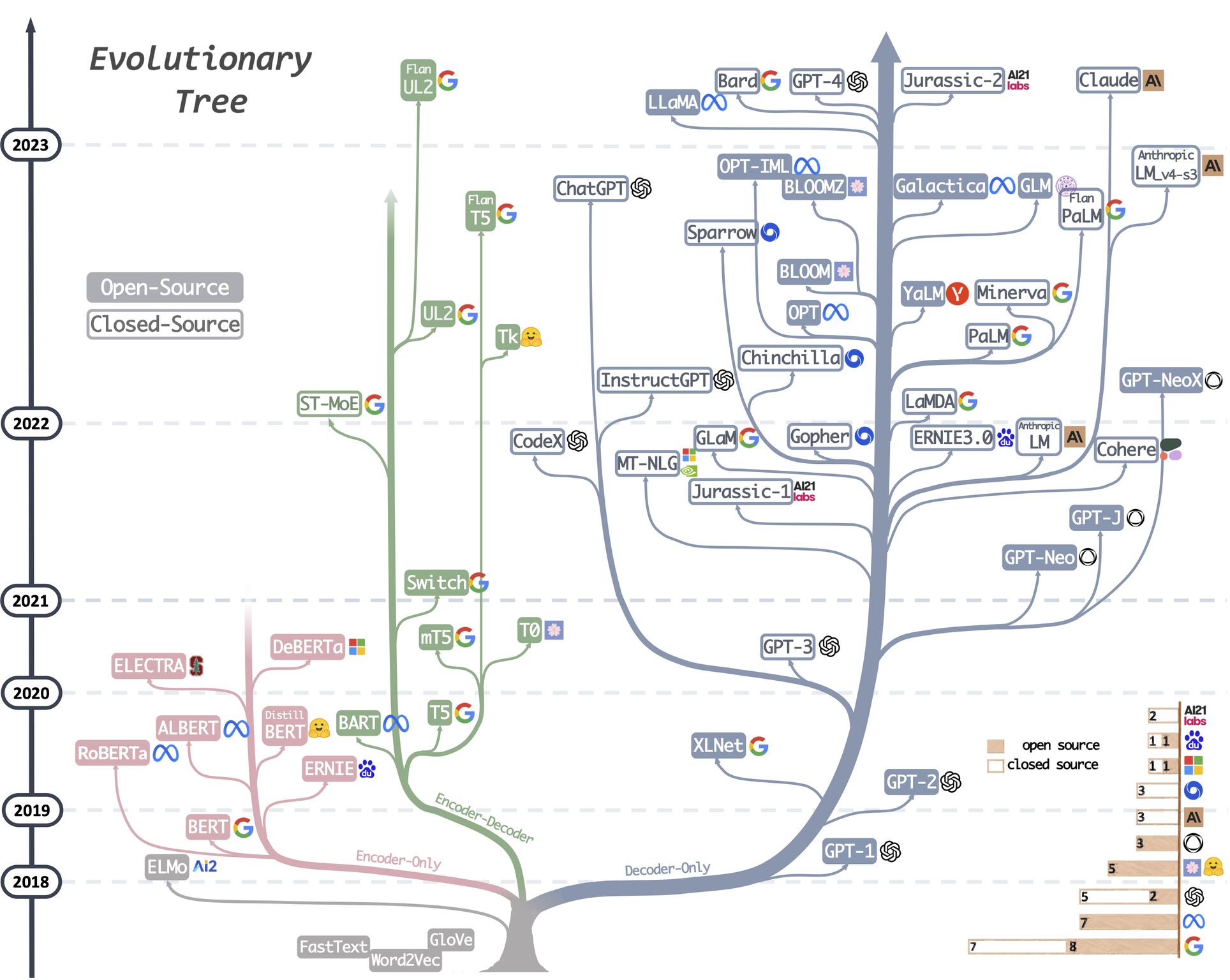
It began by introducing language modeling and language models, highlighting their significance in natural language processing tasks. The evolution of language models was then discussed, starting from statistical language models to the emergence of Large Language Models.
The presentation emphasized two key success factors in LLM: Transformers and Pre Training. Transformers, known for their ability to capture long-range dependencies, have played a crucial role in advancing LLM. Pretraining, combined with fine-tuning, has been instrumental in achieving state-of-the-art performance in various language tasks.
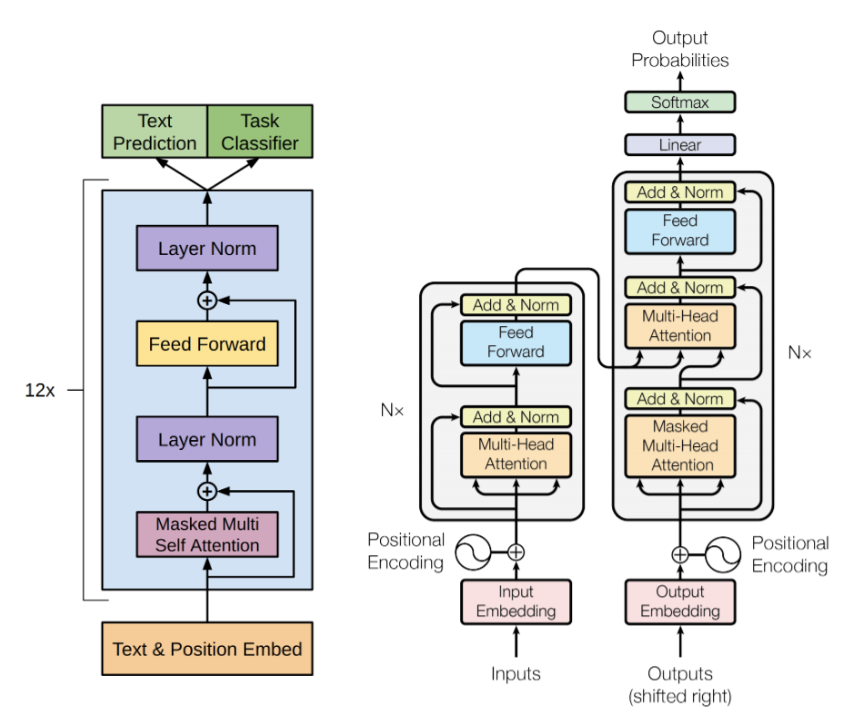
The Pretraining and fine-tuning paradigm was explained at high-level, which involves training a language model on a large corpus and then fine-tuning it for specific downstream tasks. Furthermore, the presentation also delved into the architecture of Transformers, providing a high-level understanding of encoders and decoders.
Next, different LLM variants were discussed based on transformers architecture. Encoder-only architecture was explored using BERT as an example, highlighting its strengths and limitations. Additionally, the decoder-only architecture was explained through GPT, showcasing its capabilities and constraints. The encoder-decoder architecture was also covered, with T5 serving as an example, along with its respective strengths and limitations.
Lastly, the presentation focused on the factors behind the trending popularity of decoder-only LLMs citing its SOTA performance on variety of tasks and emergent abilities.
 LLMs Reading Group Series: Introduction to Large Language Models
LLMs Reading Group Series: Introduction to Large Language Models